
Development of Online Handwriting Recognition System for Indian Languages (OHWR) - Phase II - Deployment of an application and improvement of engine performance
The ability to digitally acquire information in local languages is a necessity to eliminate redundancy in data entry of information collected for various applications like census, national missions like NHRM etc. Also data entry in local languages is a cumbersome process involving different combinations of multiple QWERTY keystrokes for each character. In order to facilitate automatic digital availability of information in local languages the need of the hour is robust recognizers for online handwriting in Indian scripts.
On-line handwriting recognition involves the automatic conversion of text, as it is written, into either letter codes / unicodes representing the character or into typed characters on editing software. The characters are acquired on a special digitizer or tablet PC dynamically, where a sensor picks up the co-ordinates of the trajectory of the stroke X(t), Y(t) from the pen-tip movements as well as the instances of pen-down and pen-up. The set of coordinates form one pen-down to next pen-up constitute a stroke. Each character is collected as a bunch of one or more strokes. The online stroke data contains both the temporal information about the writing process and the spatial shape information of the characters. A recognition engine could make use of both these information for robust performance.
We in our lab are developing an OHWR system for the regional indian language of telugu.
The set of basic characters in Telugu script consists of 16 vowels and 36 consonants. The characters in telugu script are a combination of these basic characters and their modifiers which gives rise to about 18,000 unique characters. All these unique characters in telugu can be represented as a combination of a manageable set of 235 strokes. Also the character strokes, other the first stroke taken as main stroke, can be divided, based on the position of the stroke, into 3 tiers - top stroke, bottom stroke and baseline auxiliary stroke. In online recognition of characters, the recognition problem is divided into recognizing strokes in each tier separately, and putting together the strokes to determine the character. For recognition at each stage we use an SVM based classifier.
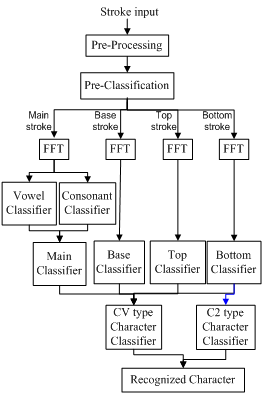 |
SVM based classification engine
Online and offline recognition approaches involve different representations of a hand written character. The issues and confusability associated with offline recognition are complementary to those associated with in online recognition. An appropriate combination of both approaches may be used to enhance the recognition accuracy. Offline recognition algorithms extract the contours of handwriting from the character image and use these for recognizing a character. The online data is converted into an image and is used for classification.
Deep Belief Networks and Convolutional Neural Networks with feedback learning have the potential to learn features by themselves.
The consonant modifier stroke is always towards the right bottom corner in the character image and is disjoint from the main character. It can be removed which reduces the number of unique characters to 556. A network for recognizing 556 characters should have 556 classes in its output layer. To minimize the complexity of the network the classification problem can be split into multiple networks as follows.
- Classify the character as a vowel or a consonant – 1 network (PV)
- If Vowel
- Recognize the vowel – 1 network (PVin)
- If Consonant
- Recognize the consonant – 1 network (C)
- Recognize the vowel modifier for the consonant – 1 network (Vm)
Thus the number of classes in the output layer reduces to 2 for PV, 16 for PVin, 36 for C and 15 for Vm networks respectively
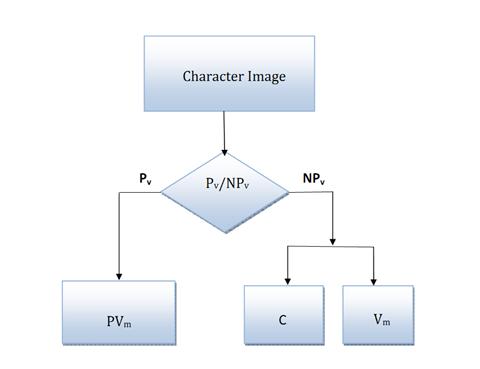 |
Separate Networks in CNN and DBN.
- Sagar Dewan, Srinivasa Chakravarthy, A system for offline character recognition using Auto-encoder Networks,
- Rajkumar.J, Mariraja K., Kanakapriya,K., Nishanthini, S., Chakravarthy, V.S., Two Schemas for Online Character Recognition of Telugu script based on Support Vector Machines, ICFHR 2012